 I was previously a user of blackhole application nd used it primarily to browse music but it slimmed into thin air ig.
I often wondered whether the same thing could happen in a browser too. I was already familiar with client-side stores like Redux and MobX, which can manage state in the browser’s memory in a much more efficient way. I was particularly fond of the functionality that allowed the application to store all recently played songs in the mobile history. And, of course, it was ad-free . I wanted to bring this experience to the web.
Sometimes, the same songs would repeat, and it almost felt like I was stuck listening to the same playlist over and over again. To discover new music, I often browsed Reddit channels for fresh recommendations. That’s when I thought—why not make this a feature in my application?
I was previously a user of blackhole application nd used it primarily to browse music but it slimmed into thin air ig.
I often wondered whether the same thing could happen in a browser too. I was already familiar with client-side stores like Redux and MobX, which can manage state in the browser’s memory in a much more efficient way. I was particularly fond of the functionality that allowed the application to store all recently played songs in the mobile history. And, of course, it was ad-free . I wanted to bring this experience to the web.
Sometimes, the same songs would repeat, and it almost felt like I was stuck listening to the same playlist over and over again. To discover new music, I often browsed Reddit channels for fresh recommendations. That’s when I thought—why not make this a feature in my application?
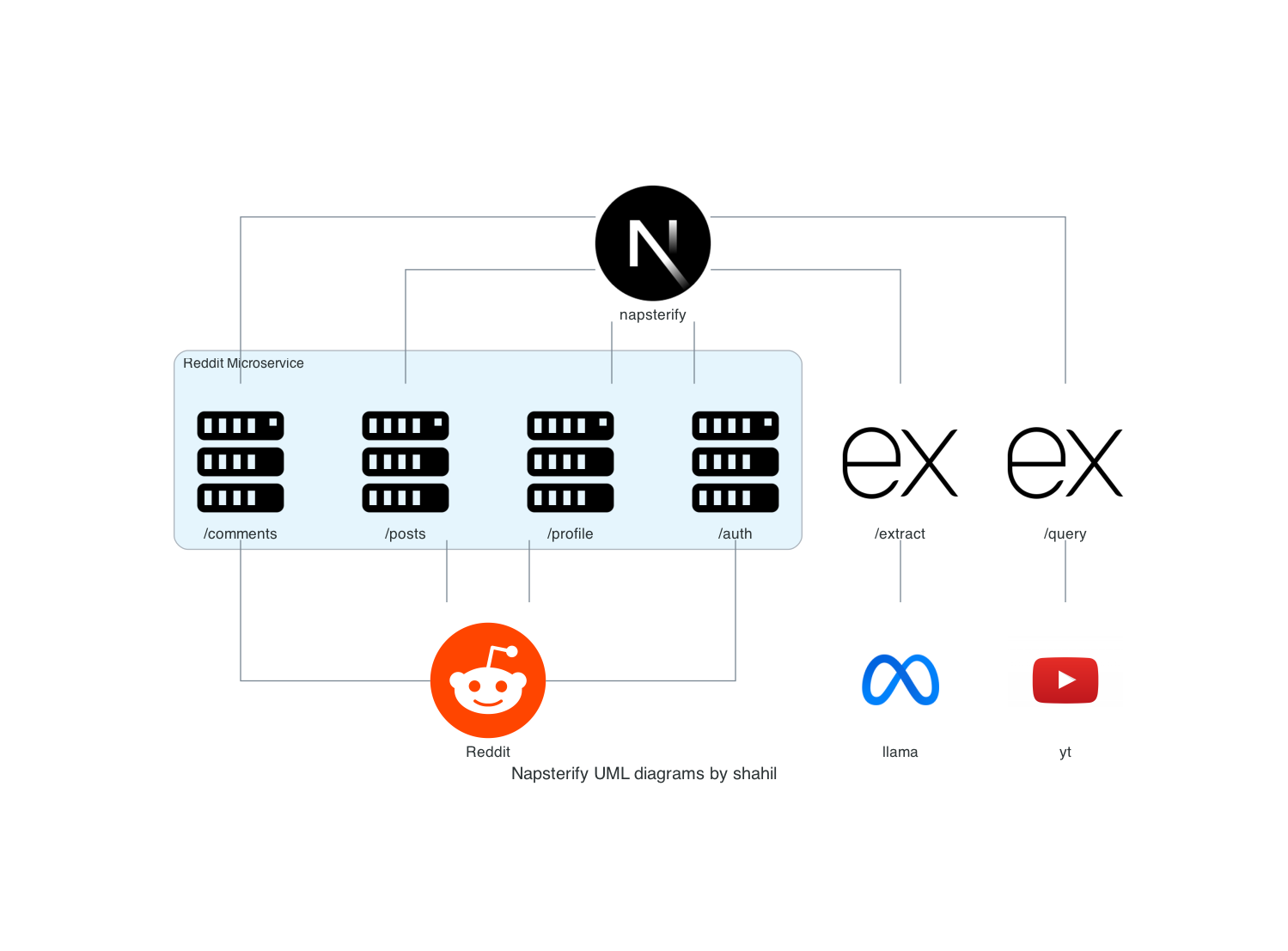
Lets delve into the overall structure
Songs
Lets first discuss where the songs are from? Its from Jiosaavn and I found an open source repo in Github made by Sumit Kolhe, where I could get the songs from. It was a Bun-managed repository that could also function as a Cloudflare Worker, acting as a serverless function deployed on their edge network instead of running as a standalone server. JioSaavn requests must be explicitly sent from India. Since Cloudflare doesn’t allow you to restrict a worker to a specific region, you can use Vercel as an alternative to deploy your API. Though it’s tricky, it’s possible. You need to bundle all your code into a single file using either esbuild or tsup, which I use.
You can find the code for my implementation, in the repository. I just added one more endpoint to populate songs on the Homepage, nothing very fancy just a small addon.
Frontend Client - NextJS
Now about the frontend client located in theapps/www directory.
 It was developed using Next.js and Redux. When using any client-side store with an SSR-based framework, it’s important to be aware that the store is scaffolded in the client’s browser because RSC (React Server Components) can’t have state by default. So, what’s the problem here? It means that the playlist of each active user could pollute the songs in another user’s playlist. Since the store would be maintained on the server, and globally there would be only one instance available, this is a behavior we want to avoid.
As for data fetching, I wanted to avoid mistakes when using traditional
It was developed using Next.js and Redux. When using any client-side store with an SSR-based framework, it’s important to be aware that the store is scaffolded in the client’s browser because RSC (React Server Components) can’t have state by default. So, what’s the problem here? It means that the playlist of each active user could pollute the songs in another user’s playlist. Since the store would be maintained on the server, and globally there would be only one instance available, this is a behavior we want to avoid.
As for data fetching, I wanted to avoid mistakes when using traditional useEffect hooks for fetching data in client components. Fetching data for server components is straightforward in Next.js, but things get complicated in client-side components, where error handling can become tedious. Fortunately, the Vercel team provides a library called swr, which takes care of these complexities for you.
The frontend client also integrates with Reddit, as I mentioned earlier, to help discover new songs in case the LLM kept recommending the same tracks in a loop. I built a custom music player using Redux in this frontend client, which manages all your playlists. Inspired by the BlackHole application, it allows you to favorite songs and store your listening history in the browser.
Session handling and authentication with Reddit are managed using NextAuth, and token refresh after a day is automatically handled by NextAuth as well.
You will hear me using the word
worker a lot. It’s the term Cloudflare uses for their serverless functions. Essentially, a worker is a serverless function deployed on their edge network.apps/fns/reddit
This was my first time creating an API service, so I made many mistakes. I am new to backend development. Initially, I tried creating different endpoints using Express and deployed them as separate servers. However, this was overkill since I was merely proxying requests from one service to another.
Then, I decided to try Hono. It also features OpenAPI specs, allowing me to follow Swagger standards for making requests directly from the browser instead of using Postman. Additionally, it made development easier by automatically generating documentation as I built the API. So, I switched to Hono. Setting it up was much easier compared to Express.
At first, I was unaware of PRAW, the Python client that manages Reddit OAuth endpoints. Because of this, I manually created the endpoints to interact with Reddit for fetching posts, comments, profile information, and communities.
AI
About the AI worker located inapps/fns/ai
It primarily analyzes Reddit comments and generates search labels, which are then passed to the YouTube worker to retrieve the video ID.
The AI worker uses Gemini in deployment mode, but you can also use other Ollama models like deepseek locally during development. You just need to make some minor changes in the code.
src/routes/query.ts
Youtube
About the YouTube worker located inapps/fns/yt
This worker retrieves the video ID from Google’s YouTube API. It’s pretty self-explanatory.